# Stages of Data Processing
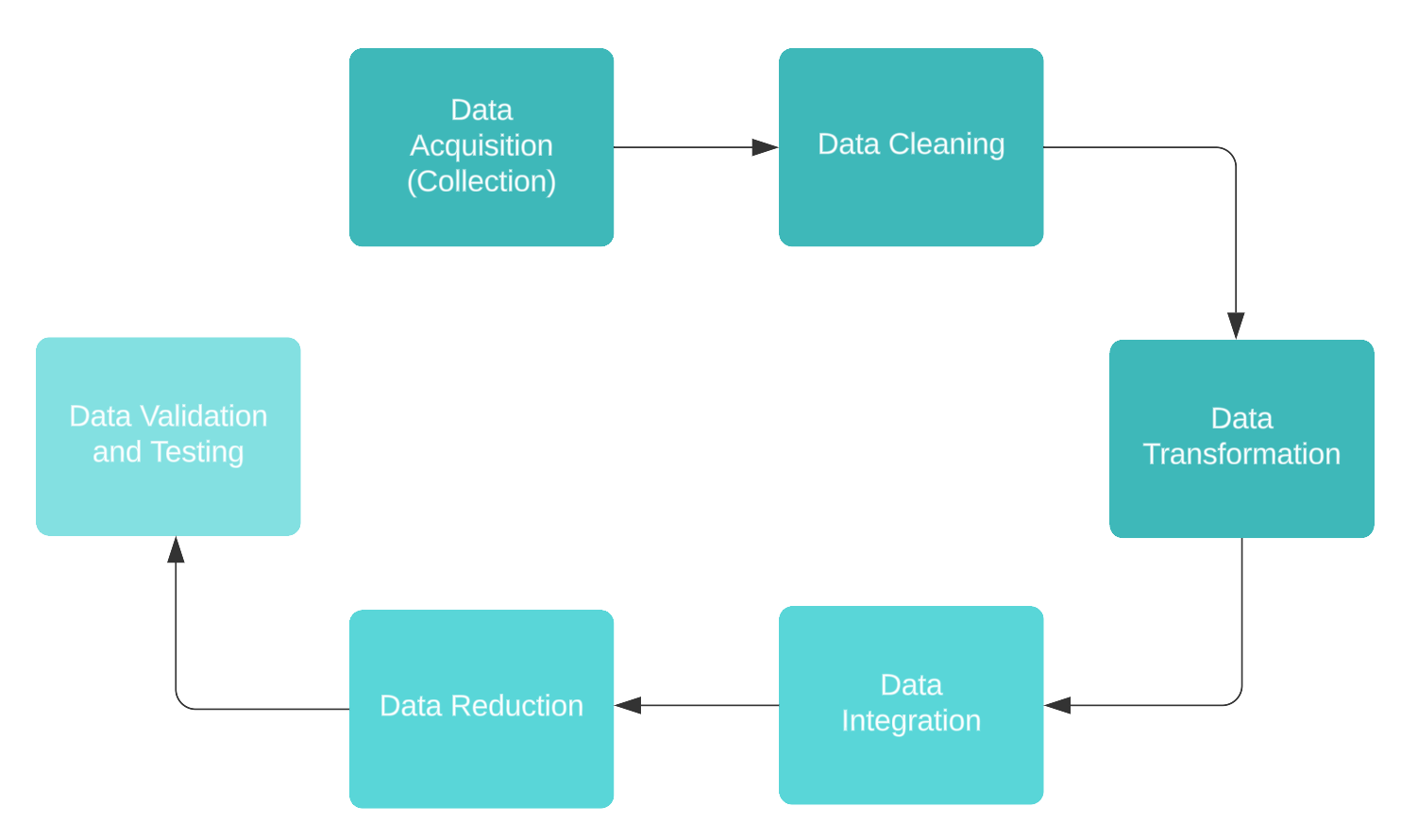
Data processing is a critical workflow in machine learning that involves transforming raw data into a structured format ready for model training. Each stage in this pipeline plays a crucial role in ensuring that data is clean, organized, and usable. Here, we break down the main stages of data processing, which include data collection, data cleaning, data transformation, data integration, and data reduction.
Stages of Data Processing
### 1. Data Acquisition (Collection)
**Data collection** is the initial step, where raw data is gathered from various sources, such as databases, APIs, web scraping, and IoT devices. This stage sets the foundation, as the quality and scope of the data collected directly impact model performance. Data collection should align closely with the project’s goals to ensure that relevant data is captured.
* **Goal:** Acquire data that is relevant, sufficient, and as complete as possible for the ML task at hand.
### 2. Data Cleaning
In the **data cleaning** stage, raw data is refined to remove inaccuracies, inconsistencies, and irrelevant information. This is essential, as real-world data often contains errors or missing values that can harm model performance. Common data cleaning tasks include handling missing data, correcting erroneous entries, and filtering outliers.
* **Example:** In a dataset of customer information, you might fill in missing values (e.g., by using the mean or median), correct inconsistent data formats, and remove duplicate records.
* **Goal:** Ensure that the data is accurate, consistent, and free of noise or irrelevant information.
### 3. Data Transformation
**Data transformation** involves modifying data into a format suitable for analysis and modeling. This stage may include encoding categorical variables, normalizing numerical features, or reshaping data into specific structures required by machine learning algorithms. Data transformation can also involve feature engineering, where new attributes are created to enhance model performance.
* **Example:** Transforming text data into word embeddings, converting categorical data into numerical labels, or normalizing values so that they fall within a specified range.
* **Goal:** Convert data into a structure and format that enhances its utility for model training.
### 4. Data Integration
**Data integration** combines data from different sources into a single, cohesive dataset. This stage is especially important when working with data from various origins or formats, such as merging internal records with external sources. Data integration often involves aligning datasets based on common keys, resolving conflicts, and ensuring consistency across all merged data.
* **Example:** Combining customer demographic data with transaction histories from different databases to create a comprehensive dataset for customer behavior analysis.
* **Goal:** Create a unified dataset that is comprehensive and consistent, enabling richer analysis and insights.
### 5. Data Reduction
In **data reduction**, data is condensed to reduce complexity without losing valuable information. This is essential when working with large datasets, as it reduces storage requirements and speeds up model training. Techniques for data reduction include dimensionality reduction, sampling, and feature selection.
* **Example:** Using Principal Component Analysis (PCA) to reduce the dimensionality of a large set of features, or selecting only the most relevant features for the model.
* **Goal:** Simplify the dataset, removing redundancy and irrelevant information to make the processing and modeling stages more efficient.
### 6. Data Validation and Testing
**Data validation** is the final step before data is fed into machine learning models. This stage verifies that the processed data is of high quality and suitable for model training. Data validation may involve checks for consistency, integrity, and adherence to required formats, along with testing samples to detect any remaining errors.
* **Example:** Running statistical tests to verify data distributions or checking that transformations have not introduced any biases.
* **Goal:** Ensure that the dataset is accurate, reliable, and ready for use in training and testing ML models.
### Summary
These stages of data processing — collection, cleaning, transformation, integration, reduction, and validation — ensure that raw data becomes a refined, high-quality input for machine learning models. Mastering each stage of the data processing pipeline allows for more robust and accurate models, ultimately leading to better insights and predictions in real-world applications.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://apphp.gitbook.io/artificial-intelligence-with-php/machine-learning/data-fundamentals/ml-data-processing/stages-of-data-processing.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.